🥇 Сравнение Нашей Системы STT с Остальными Системами на Рынке по Качеству
Если вы еще не познакомились с нашей статьей, то самое время прочитать. Обязатально прочитайте и возвращайтесь!
 Alexander Veysov
Alexander Veysov
- Оригинальная редакция февраль 2020 года;
- [Обновление 25.03.2020] Обновлены тесты некоторых систем, обновлены наши результаты;
Методология Тестирования
Итак, протестировать любую систему можно следующим образом:
- Выбрать и разметить набор валидационных датасетов;
- Опросить все публично доступные сервисы;
- Нормализовать результаты (это можно сделать например нашей публично доступной системой нормализации);
- Посчитать WER;
Вопрос, естественно, всегда состоит в выборе доменов на которых нужно тестировать модели. Все всегда делают оговорки, что их система настраивалась на какой-то определенный домен, поэтому по-настоящему убедиться в качестве работы системы можно только протестировав ее на большом разнообразии данных из разных доменов.
Список и Описание Доменов
Чтобы быть минимально предвзятым, мы выбрали следующий список доменов разной степени приближенности к реальным данным:
- Чтение. Самый простой и далекий от реальности домен - люди читают в микрофон. Качество идеальное, словарь не очень большой;
- Звонки (такси). Реальные звонки в такси. Словарь перекошен в сторону адресов, качество среднее;
- Публичные выступления. Зоопарк кодеков и форматов, большой словарь, довольно высокое качество;
- Радио. Зоопарк кодеков и форматов, большой словарь, среднее качество;
- Заседания суда. Большой словарь, перекошенный в сторону юридических терминов, среднее качество записи;
- Аудио книги. Высокое качество речи, монотонные интонации, большой словарь;
- YouTube. Зоопарк форматов, много шума, зоопарк по качеству - от идеального до плохого, часто есть много музыки и шума на заднем фоне;
- Звонки (e-commerce). Довольно среднее качество аудио, много очень специфичной лексики;
- "Yellow pages". Звонки в различные бизнесы с целью бронирования и записи. Низкое и среднее качество, малый словарь, много артефактов телефонии и шумов;
- Медицинские термины. Стресс-тест моделей. Низкое качество записи, все аудиозаписи содержат "непонятные" обычному человеку термины. Мы убрали все записи, где нет таких терминов;
- Звонки (пранки). Низкое качество, много обсценной лексики, очень много шумов, очень неровные интонации;
Результаты
[Обновление 25.03.2020] Результаты нашей модели стали лучше, по сравнению с оригинальной публикацией результатов в данной статье, на следующих доменах:
- Аудио книги 1 процентный пункт WER;
- YouTube 1 процентный пункт WER;
- Радио 1 процентный пункт WER;
- Публичные выступления 1 процентный пункт WER;
- Звонки (такси) 1 процентный пункт WER;
- Звонки (пранки) 1 процентный пункт WER;
- Заседания суда 1 процентный пункт WER;
- "Yellow pages" 2 процентных пункта WER;
Мы протестировали большую часть доменов на следующих системах ([Обновление 25.03.2020] - если не указано, что результаты обновлялись то мы или делали ограниченные тесты и ничего не поменялось, или не было основания полагать, что что-то поменяется):
- Tinkoff. [Обновление 25.03.2020] - мы слышали отзывы, что качество системы сильно выросло, прогнали все тесты заново, это действительно так;
- Yandex SpeechKit. [Обновление 25.03.2020] - мы не обновляли все тесты, но кое-что мы тестировали заново, результаты особо не менялись. Мы слышали про "новую модель", но никто нам так толком и не сказал, как ее вызвать;
- Kaldi 0.6, Kaldi 0.7. [Обновление 25.03.2020] - недавно вышла версия Kaldi 0.7 и мы прогнали все тесты через нее через vosk-api. Обнаружили, что на исторических данных kaldi напрямую и через vosk-api показывал разные показатели в разное время, решили оставить самые лучшие, чтобы не быть предвзятыми;
- Wit.ai;
- Google;
- ЦРТ (звонки, общая модель, медицина, телеком, финансы);
- Speech Analytics (stt.ai);
- Azure;
Большая часть тестов проводилась с использованием публичных АПИ описанных выше сервисов в конце 2019 начале 2020 года. Мы использовали ОДНУ И ТУ ЖЕ нашу модель без разных словарей под каждый домен, за исключением такси. В такси словарь улучшал WER на ~1 процентный пункт. Мы обновляли тесты для моделей, где было известно, что качество сильно выросло или был публичный новый релиз.
| Домен | Систем лучше | Систем хуже | Наш WER | Лучший WER | Худший WER |
|---|---|---|---|---|---|
| Чтение | 2 | 14 | 10% | 3% | 29% |
| Звонки (такси) | 0 | 17 | 13% | 13% | 86% |
| Публичные выступления | 0 | 16 | 15% | 15% | 60% |
| Радио | 0 | 16 | 18% | 18% | 70% |
| Заседания суда | 0 | 7 | 21% | 21% | 53% |
| Аудио книги | 4 | 14 | 27% | 22% | 70% |
| YouTube | 1 | 17 | 31% | 30% | 73% |
| Звонки (e-commerce) | 2 | 13 | 32% | 29% | 76% |
| Yellow pages | 1 | 6 | 33% | 31% | 72% |
| Медицинские термины | 1 | 6 | 40% | 39% | 72% |
| Звонки (пранки) | 3 | 14 | 41% | 38% | 85% |
Результаты по Каждому Домену Отдельно
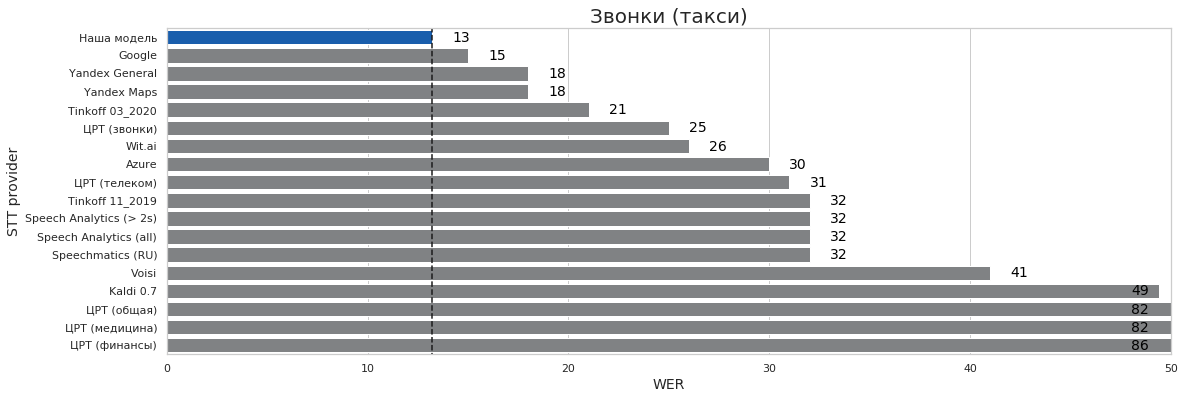
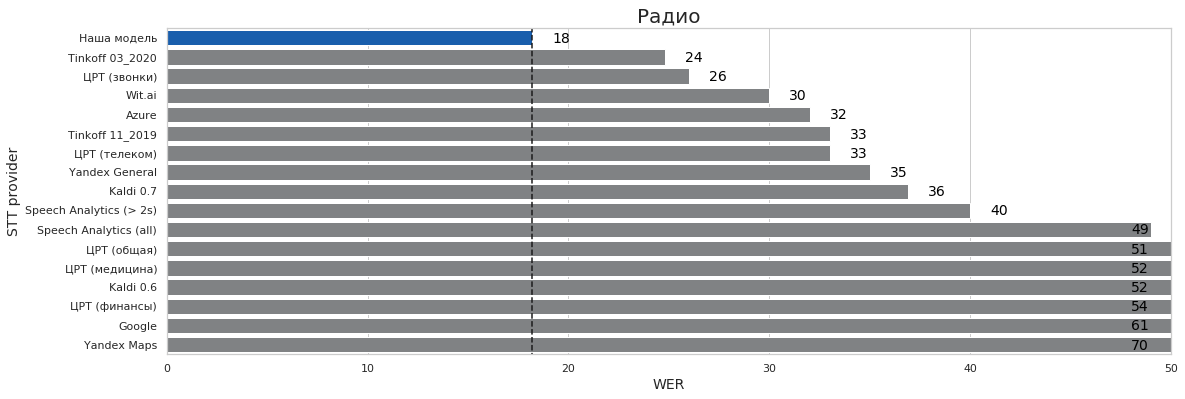
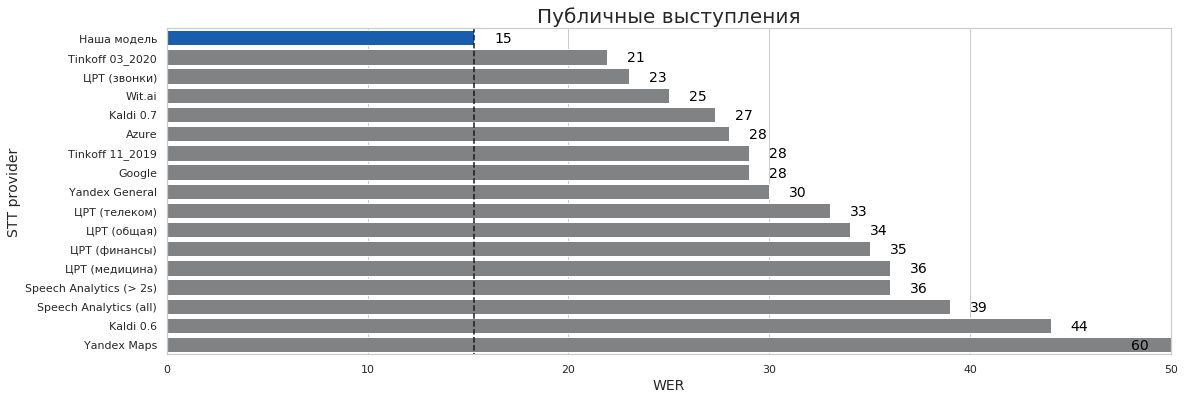
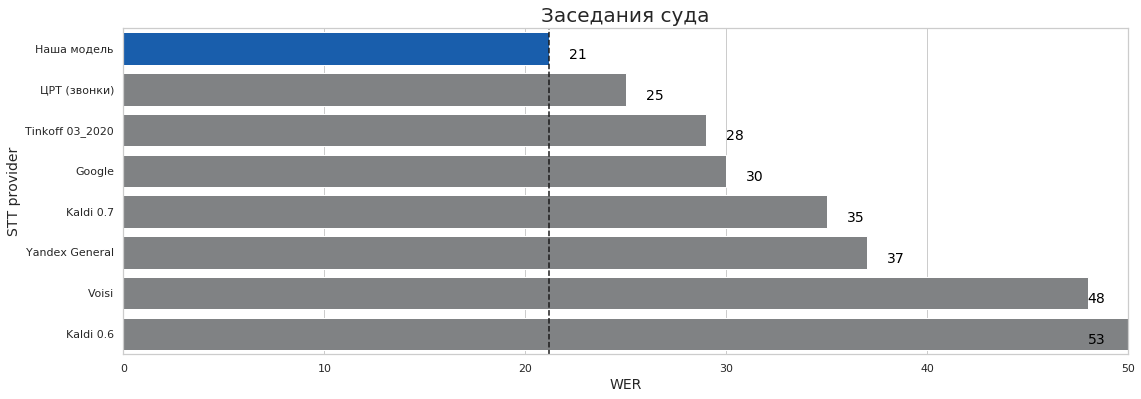
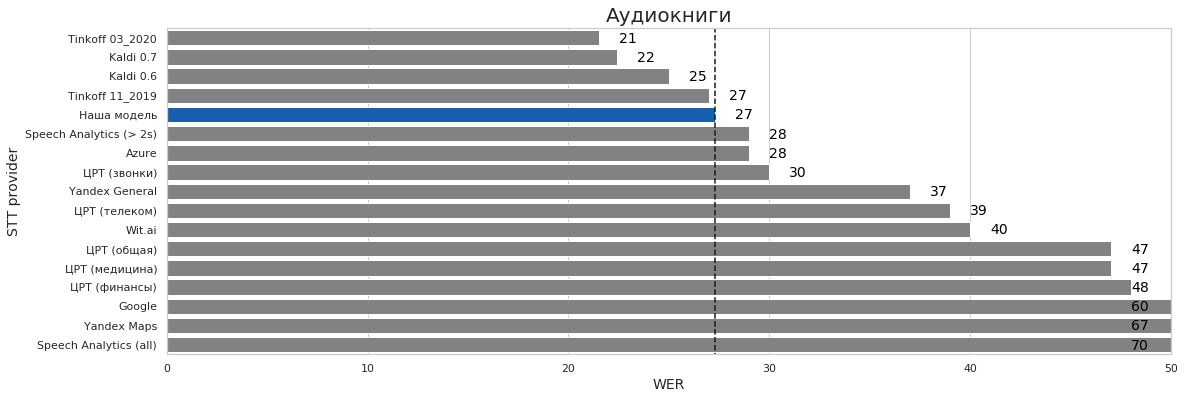
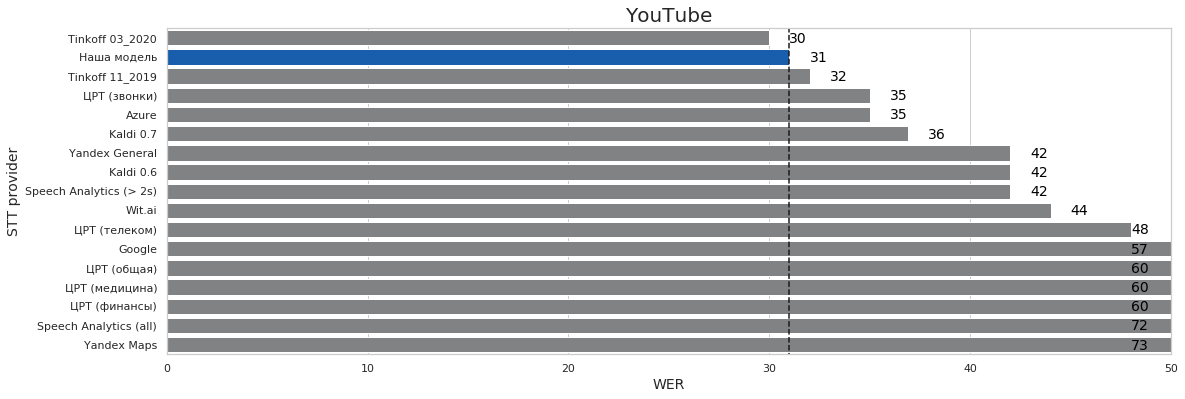
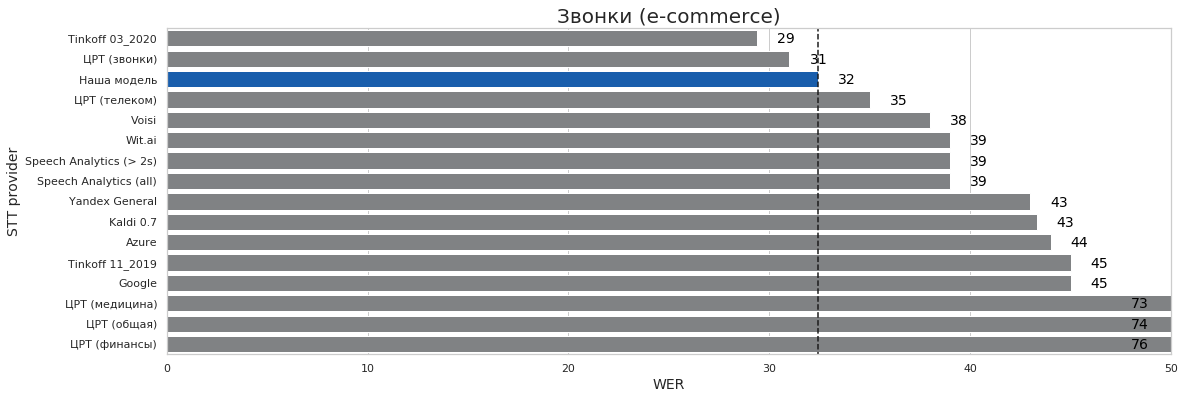
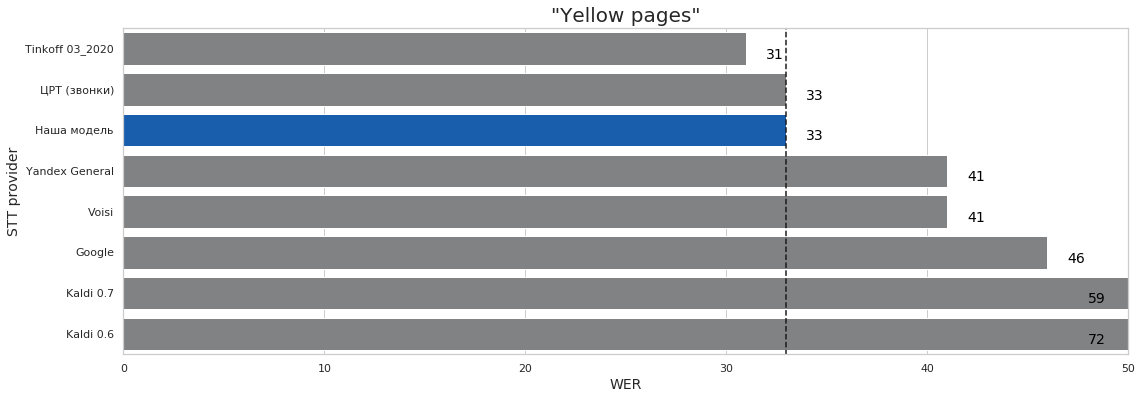
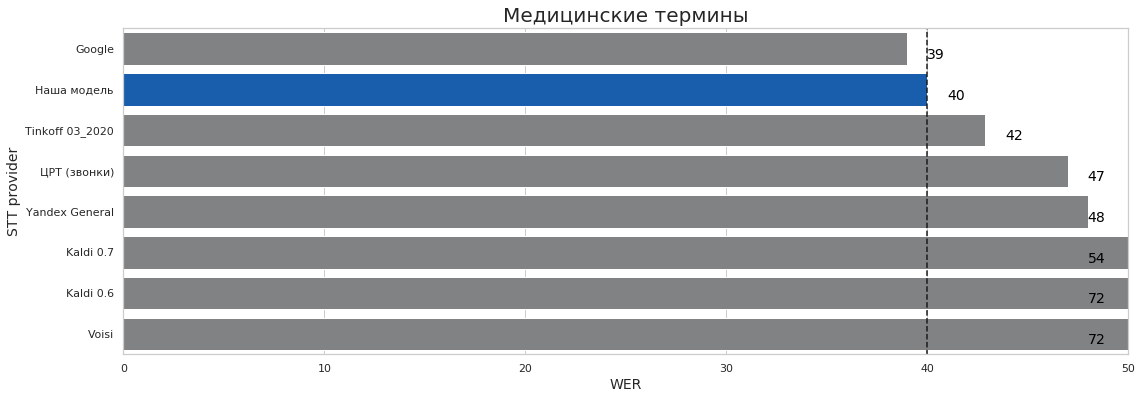
Выводы
- У нас единственная модель на рынке, которая хорошо работает вообще на всех представленных доменах, даже тех, где нет размеченных данных;
- Второй подобной почти универсальной моделью является модель ЦРТ для звонков (остальные публичные модели по сути просто не работают на in-the-wild данных), но она показывает более низкие метрики на 8 из 11 датасетов;
- На тех моделях и датасетах что мы тестировали, Яндекс даже близко не является лидером рынка по качеству;
- Судя по результатам - модели Kaldi и сервисы на основе Kaldi тренировались на аудиокнигах, на которых они показывают хорошее качество. Но на более шумных доменах - разница в качестве между лидерами и Kaldi составляет в среднем примерно 2 раза;
- Тinkoff существенно опережает всех на аудио с идеальным качеством (чтение), но на остальных доменах качество посредственное;
[Обновление 25.03.2020]
- Несмотря на сильную конкуренцию со стороны новой модели Tinkoff, наша модель все равно единственная, которая показывает отличные или хорошие результаты на всех перечисленных выше доменах;
- Сейчас получается, что на рынке есть всего 2 более менее универсальные модели (кроме нашей) - ЦРТ и Tinkoff;
- Сейчас у нашей модели абсолютно лучший результат на 4 из 11 доменов. Результат несущественно отличающийся от лидера на этом домене - на 9 из 11 доменов. Сильно проигрывают по сути только аудио книги и чтение, но эти домены не являются прикладными;
- Мы так до конца и не поняли, что за "новая модель" Яндекса. Мы тестировали публично доступные модели повторно на выборках из наших датасетов - разницы не увидели;
- Новый релиз Kaldi 0.7 от Николая Шмырева стал сильно лучше почти на всех датасетах по сравнению с Kaldi 0.6, в том числе даже на очень шумных данных. Kaldi продолжает неплохо работать на книгах и очень чистых данных. Но на остальных доменах качество все равно остается очень низким - ошибок в 2-3 раза больше, чем у лидеров. Например на такси - в 3-4 раза больше ошибок;
- Мы также повторно проверяли качество Google на небольших выборках, там тоже особо не было разницы;
- Судя по качеству распознавания, можно сделать вывод, что свою модель Тинькофф тренирует на своих звонках, аудио книгах и аудио с YouTube;
- Kaldi вероятнее всего тренируется на аудио книгах;