🧪Тестируем Качество Диаризации на Реальных Данных
Мы видели разные маркетинговые материалы на тему точности определения спикеров / идентификации / аутентификации спикеров. Как правило это или довольно непонятные академические метрики на идеализированных модельных данных или метрики вроде 99.999% для text-dependent систем (надо говорить одно и то же слово).
Давайте для простоты назовем задачу разделения высказываний спикеров в рамках одного аудио "диаризацией" и примем предположение, что они почти не говорят одновременно. Не так давно нам дали пару небольших датасетов и мы провели небольшое исследование того, как себя ведут наши алгоритмы на них.
Данные
Чтобы лишний раз не заниматься ручной разметкой для диаризации, данные мы взяли следующие:
- Один часовой диалог между 3 спикерами, аудио есть как смешанное, так и поканальное. Также отдельно есть по дополнительному часу речи на каждого из спикеров (видимо из другого диалога);
- Один часовой диалог между 7 спикерами, аудио есть как смешанное, так и поканальное (на самом деле это собранные вместе 2 встречи, так как на одной из них было мало спикеров);
- Длины смешанных и одноканальных аудио идеально совпадают.
Разметка
Имея такие данные, можно несложным алгоритмом понять точно, где говорят конкретные люди:
- Нарезаем каждое одноканальное аудио на высказывания конкретного спикера;
- Убираем тишину и кусочки речи, короче чем одна секунда;
- Запоминаем когда кто говорил и применяем эту нарезку к смешанному аудио;
- Далее разделяем высказывания одного спикера на "тренировочную" и "валидационную" выборки;
- Голосовые слепки для конкретного спикера считаются на основе "тренировочной" выборки, как на смешанном аудио, так и на одноканальных аудио. Получается соответствие 1 спикер - 1 голосовой слепок;
- Голосовые слепки на валидационной выборке могут считаться как на том же аудио, так и на другом, если оно есть;
- Валидационная выборка сильно больше тренировочной (вопреки обычной ситуации);
В качестве меры близости используем простое косинусово расстояние, то есть мы просто ищем какой конкретный маленький "кусочек" речи ближе к какому голосовому слепку.
Понятно, что результаты можно улучшить поиском не к центроиде, а к набору центроид или высказываниям или придумать миллион эвристик и усложнений, но мы ставили задачу оценки только базового качества, без изысков.
Результаты на 7 спикерах
На аудио с 7 спикерами у нас было по сути одно аудио. Поэтому мы смогли только проверить только влияние того, как мы считаем голосовой слепок - по смешанным или одноканальным аудио (разницы не было). Результаты получились следующие:
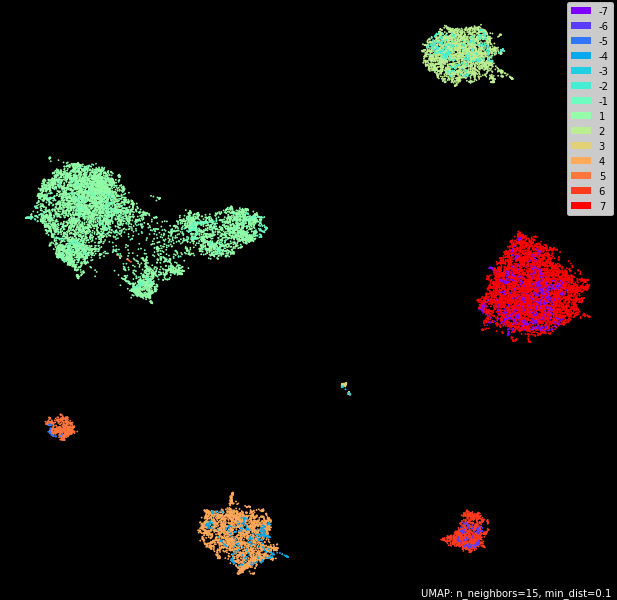
На графике:
- Отрицательные "классы" - это кусочки, которые использовались для расчета голосового слепка на тренировочной выборке;
- Положительные "классы" - это уже валидационная выборка;
- Хорошо видно, что один спикер использовал два разных устройства;
| Спикер | Точность, % | Трейн, секунд | Трейн, штук | Вал, секунд | Вал, штук |
|---|---|---|---|---|---|
| 1 | 99.98 | 102 | 503 | 1400 | 5428 |
| 2 | 99.99 | 51 | 541 | 501 | 7455 |
| 3 | 77.01 | 4 | 19 | 17 | 87 |
| 4 | 99.7 | 50 | 100 | 460 | 1011 |
| 5 | 94.2 | 5 | 22 | 91 | 483 |
| 6 | 99.51 | 20 | 265 | 190 | 2467 |
| 7 | 99.78 | 95 | 268 | 1000 | 2671 |
Напрашивается очевидный вывод - алгоритм реагирует на устройство записи, но в рамках одного разговора почти идеально разбивает говорящих на классы.
Результаты на 3 спикерах
Тут все получается немного интереснее, так как можно посчитать "тренировочные" голосовые слепки как на том же аудио, так и просто на дополнительном часовом одноканальном аудио.
"Тренируемся" на том же диалоге на смешанном аудио
Тут результат аналогичный.
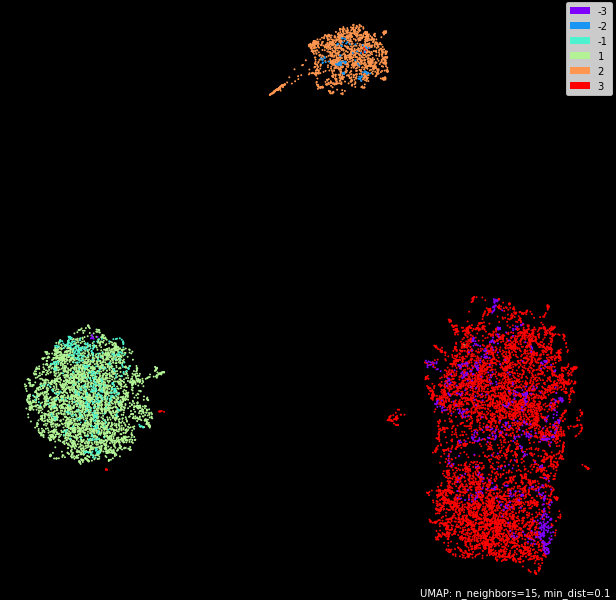
| Спикер | Точность, % | Трейн, секунд | Трейн, штук | Вал, секунд | Вал, штук |
|---|---|---|---|---|---|
| 1 | 99.26 | 65 | 461 | 708 | 3663 |
| 2 | 97.56 | 21 | 74 | 260 | 1395 |
| 3 | 99.71 | 114 | 731 | 1300 | 6579 |
"Тренируемся" на том же диалоге но на одноканальных аудио
Результат тоже очень похожий.
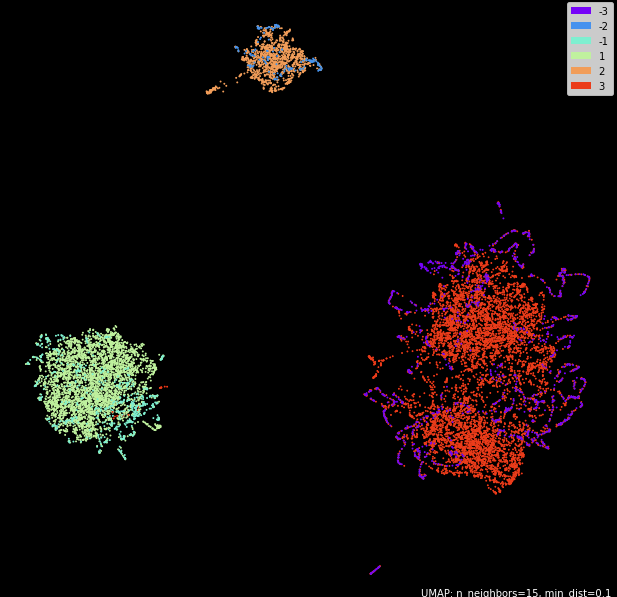
| Спикер | Точность, % | Трейн, секунд | Трейн, штук | Вал, секунд | Вал, штук |
|---|---|---|---|---|---|
| 1 | 99.52 | 100 | 532 | 600 | 3766 |
| 2 | 96.56 | 27 | 141 | 370 | 1200 |
| 3 | 99.54 | 220 | 1164 | 1400 | 6711 |
"Тренируемся" на другой речи этого спикера (дополнительный час аудио)
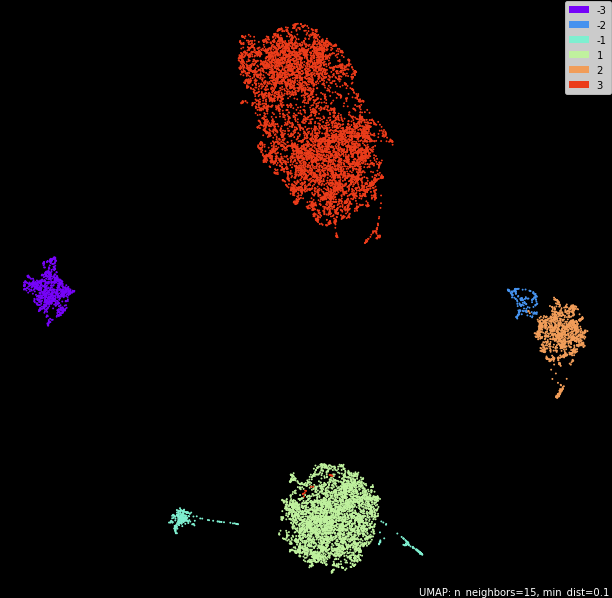
| Спикер | Точность, % | Трейн, секунд | Трейн, штук | Вал, секунд | Вал, штук |
|---|---|---|---|---|---|
| 1 | 98.46 | 67 | 354 | 600 | 3766 |
| 2 | 94.63 | 34 | 180 | 370 | 1200 |
| 3 | 81.69 | 165 | 877 | 1400 | 6711 |
Тут уже видно, что для спикеров 1 и 2 ситуация похожа на прошлые эксперименты, а вот у спикера 3 (на графике 3 и -3) уже сильно отличаются микрофоны.
"Тренируемся" на всей речи этого спикера из дополнительного часа аудио
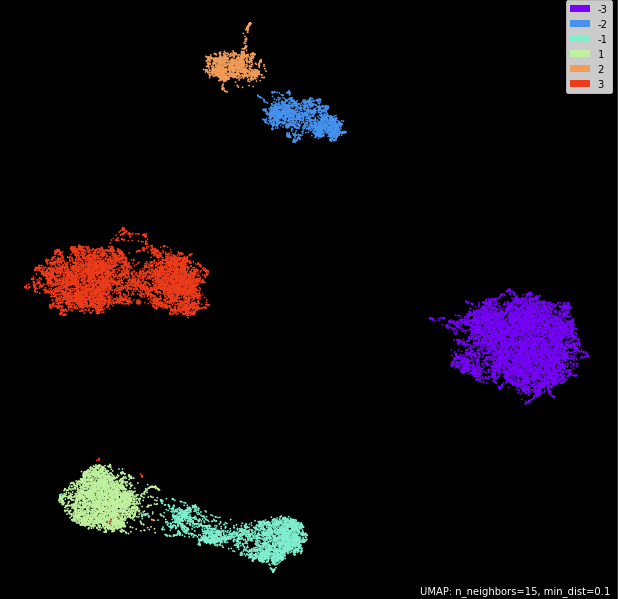
| Спикер | Точность, % | Трейн, секунд | Трейн, штук | Вал, секунд | Вал, штук |
|---|---|---|---|---|---|
| 1 | 99.51 | 600 | 3300 | 700 | 3700 |
| 2 | 95.48 | 360 | 2000 | 260 | 1350 |
| 3 | 86.11 | 1400 | 7600 | 1250 | 6700 |