⏲ Скорость Систем STT
Нам приходилось слышать абсолютно разные оценки скорости (ну или наоборот - оценки потребности в железе) систем распознавания речи, отличающиеся даже на несколько порядков. Также не помогает то, что некоторые системы работают на GPU, а некоторые нет, равно как и то, что ядра процессоров могут отличаться в разы по производительности (например старые серверные процессора с тактовой частотой 2 - 2.5 GHz против современных решений от AMD с 4 GHz на ядро). Давайте в этом вместе разберемся, на самом деле, все не так уж и сложно!
Как правило, по скорости и требуемому железу можно даже косвенно делать выводы о качестве распознавания (оно сильно коррелирует с обучаемостью системы и скоростью внедрения инноваций). Как правило люди начинают задумываться о скорости в 3 случаях:
- Когда ее не хватает или когда она является узким горлышком;
- Когда со скоростью нет проблем, но есть проблемы с ценой железа;
- Когда есть требования по скорости "первого ответа" и всего ответа от сервиса;
Но давайте для начала определимся с понятиями.
Определения
Такой пример скорее является исключением в западном STT коммьюнити, но лаборатория Facebook AI Research в последнее время активно наращивает свои позиции в распознавании речи и зачастую публикует интересные исследования, а в частности интересна недавняя статья, где они публикуют кроме всего прочего оценки скорости работы своих систем распознавания речи. Но как вы понимаете, обычно в таких статьях очень мало пишут про скорость и вообще прикладные вещи.
В частности, в статье приводятся 3 основные метрики, которыми обычно оценивается "скорость":
- Throughput - сколько потоков распознавания система может обрабатывать параллельно. Для простоты назовем это "потоками";
- Real time factor (RTF) - насколько каждый поток распознавания распознается быстрее, чем реальное время. Давайте для простоты определим Real Time Speed (RTS) как 1 / RTF, то есть количество секунд аудио, которое можно обработать за 1 секунду;
- Latency - какую реальную задежку чувствует конечный пользователь прежде чем ему начинают приходить ответы системы;
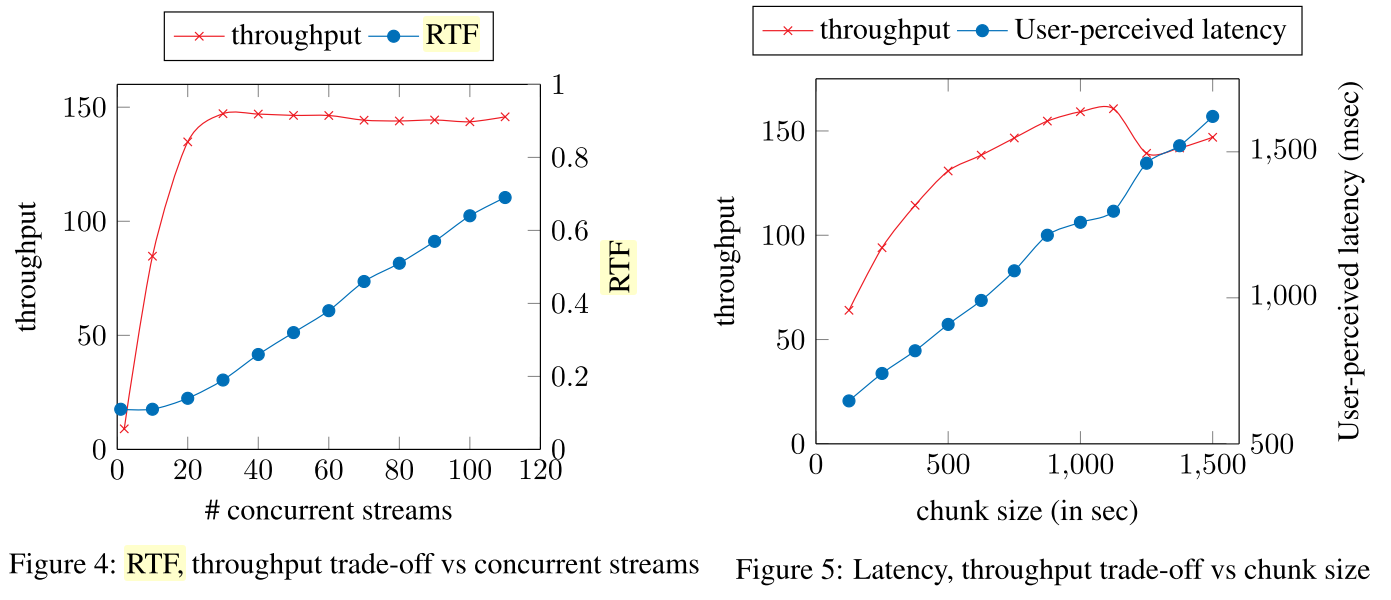
FAIR потратили существенное время на оптимизацию своей нейросети, т.к. этой статьей они продолжают по сути целое направление своих исследований, где они пиарят так называемые TDS-слои. В этой статье их ноу-хау по сути является несколько технических оптимизаций по скорости и квантизация. С определенной натяжкой, можно сказать, что они сделали что-то близкое к state-of-the-art для быстрых и практичных сетей (конечно как обычно близко без гарантий, что вы сможете это повторить).
В статье FAIR пишут, что их "оптимальные" характеристики это 40 потоков, 0.26 RTF и задержка в районе одной секунды (вообще на самом деле можно выбрать любые точки на графиках выше). Понятное дело, всегда можно перенастроить такую систему допустим на больше потоков ценой задержки, ну или допустим на меньшую задержку ценой общей пропускной способности.
Пересчитаем 40* 1 / 0.26 и разделим на 18 физических ядер процессора. Получаем, что за 1 секунду на 1 ядре серверного процессора они могут распознать где-то в районе 8-9 секунд аудио, что для скорее всего слабых ядер Xeon в принципе впечатляет.
Скорость Других Решений
Возникает закономерный вопрос - а какую скорость показывают другие системы на рынке?
| Система | RTS на 1 ядро | Тактовая частота ядра | Источник информации | Комментарий | |
|---|---|---|---|---|---|
| Kaldi 0.6 | 1 - 2 | 2-3 GHz | Комментарии разработчиков | ||
| Kaldi, activebc.ru | 3 - 4 | 2-3 GHz | Устные комментарии activebc | ||
| Система неизвестна, speechanalytics.ru | 1 | 5 Ghz в режиме турбо буст) | Ссылка | ~500 минут аудио в час | |
| Kaldi на GPU, voisi | 10 | не имеет значения | Ссылка | тут для акустической модели используется GPU | |
| Решение от FAIR | 8 - 9 | 2.6 GHz | Статья |
Конечно получается весьма негусто. Из всех систем на рынке, которые публикуют подобную информацию (конфиг по железу + скорость) или такая информация является более или менее известной (для Kaldi), получается, что потолок где-то в районе 3-4 RTS. Пусть вас не пугает цифра 10 RTS - это скорость с использованием видеокарты (скорее всего там инстанс с 4-ядерным процессоров и GTX 1080, авторы заявляют 40 RTS). Забегая вперед, скажу, что 10 это скорее некий боттлнек, который формируется за счет оверхеда на процессинг и пинга на инстансе с 4 ядрами.
Скорость Нашего Решения
Сразу оговорюсь, мы тестировали наше решение на 2 конфигурациях железа:
- CPU only, 1 ядро 3.5GHz;
- GPU (GTX 1080) для акустической модели, CPU для пост-процессинга, 1 ядро 3.6 GHz;
Здесь важно понимать, что основные вычисления ложатся именно на акустическую модель, которая может запускаться на GPU. Языковая модель не требует особой нагрузки на процессор, а просто занимает время. Поэтому получается, что при использовании GPU все "замедляется" исключительно по причине наличия оверхеда по получению файлов по сети / логов / проверок итд итп. В разных сценариях наша система показывала следующие характеристики:
- Сама акустическая модель без пост-процессинга вообще работает со скоростью 500 - 1000 RTS в секунду и по сути ограничение тут уже является I/O, но такой сценарий на практике мы пока не довели до продакшена (допустим с декодером в виде другой нейросети), ну или качества просто недостаточно;
- CPU + GPU, 20-25 RTS на 1 ядро. Идеальный сценарий, когда все файлы уже заранее лежат на диске в формате WAV. Здесь мы измеряем по сути только идеальную скорость чтения WAV файлов, скорость их прокачки через акустическую модель и скорость пост-обработки. В этом сценарии пост-процессинг делался с аккумуляцией промежуточных результатов в 8 потоков. Но в сценарии реального деплоя пост-процессинг у нас по сути уже влияет только на задержку, а не пропускную способность. Этот сценарий идеальный, поскольку тут практически 100% времени и ресурсов уделяется только "полезной работе"
- CPU + GPU, 10 RTS на 1 ядро, 40 RTS на один сервер. Это сценарий текущего (на момент написания статьи) деплоя в нашем публичном АПИ. Время тратится прежде всего на получение аудио по сети, проверку файлов, асинхронность и обмен сообщениями, оверхед на логи и сервис, минимальное ожидание следующего батча. Все эти вещи в сумме существенно влияют на производительность. На таком сервере GPU является недостаточно загруженной, поэтому если поставить 8 или 12 ядерный процессор, то можно ожидать кратного роста производительности. Естественно никто не мешает крутить не одну, а несколько моделей параллельно;
- Только CPU, 7-8 RTS на ядро. Идеальный сценарий, при котором мы сначала обрабатываем все аудио акустической моделью, а потом уже делаем пост-обработку. Если доводить такой сценарий до боевого состояния, то разумно ожидать, что итоговая скорость скорее всего снизится до 5-6 RTS на ядро за счет оверхеда. Здесь нет затрат времени на сбор батчей, поэтому падение будет не таким выраженным;
- Также в ближайшем будущем скорее всего мы доведем до продакшена свои наработки по квантизации и минификации моделей. По сути это означает, что на CPU-only можно будет рассчитывать на прирост по производительности в 2-4 раза;
Нужен ли Стриминг? Какие Гарантии по Задержке?
На самом деле, конечно не нужен, если на стороне пользователя есть компетенция по тому, как разрезать аудио на части, допустим длиной до 5 или 10с. Но на практике мы сталкивались с тем, что в реальной жизни все неоднозначно. Кто-то имплементировал себе gRPC по ряду причин, кто-то не может использовать стриминг по определению, но может настроить бизнес-процесс, чтобы он был не нужен. Но никто из тех, с кем мы бы не общались, не готов внедрять даже готовые (!) решения с открытым кодом по подготовке аудио на своей стороне.
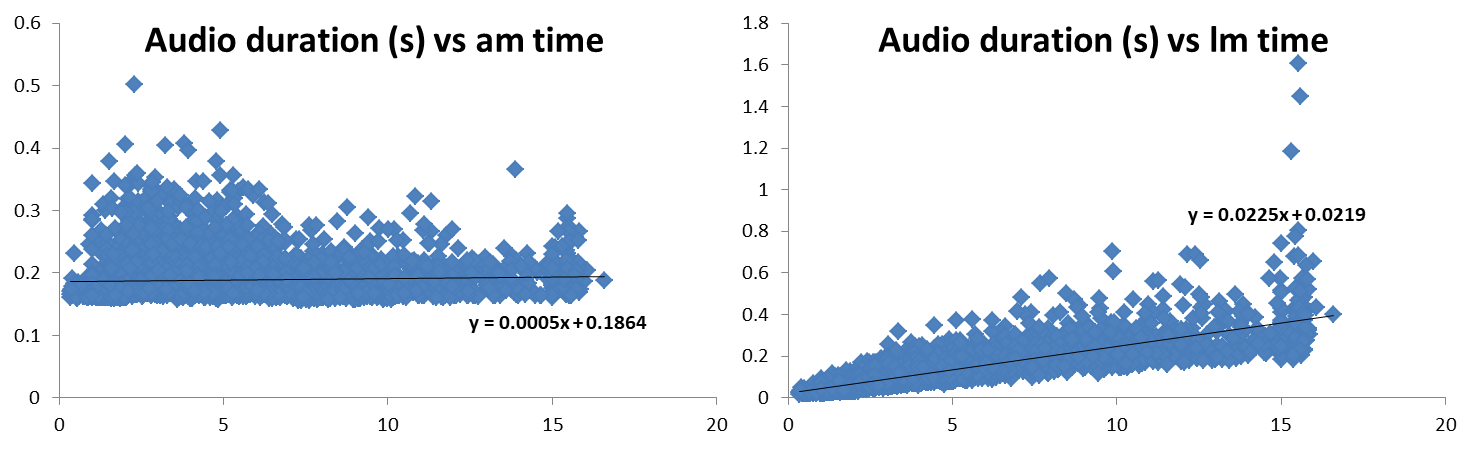
Вот один небольшой кейс на данных одного из наших клиентов за небольшой промежуток времени (те, у кого нет стриминга). Мы измеряли зависимость времени, потраченного на акустическую модель и пост-процессинг в зависимости от длины присланного аудио (у нас работает механизм, который разбивает все аудио на максимум 15-20-секундные кусочки с речью). Получается на самом деле, что использованием GPU нет разницы вообще какой длины аудио.
С 5 секундным аудио реально уложиться где-то в 300ms, а с 10-секундным где-то в 400ms. И это все с учетом ожидания 100ms на формирование батча аудио (мы пока не оптимизировали этот показатель, скорее всего можно его тоже урезать в несколько раз)! Понятное дело, сверху нужно добавить пинг в обе стороны до сервера.
Что эти Цифры Значат на Практике?
40 RTS - много это или мало? На самом деле получается, что можно распознать где-то в районе 30,000 часов аудио в месяц.