🦄 Enterprise Edition Версия Silero - Скорость, Пропускная Способность и Сайзинги
Обновление от 2023-10-25
Сейчас в список наших основных поддерживаемых решений входят:
- Программный модуль "СИЛЕРО" для синтеза речи на русском языке и сопутствующих задач на основе нейронных сетей и алгоритмов машинного обучения (ссылка, Реестровая запись №15935);
- "Программный модуль "СИЛЕРО" для распознавания речи и сопутствующих задач на основе нейронных сетей и алгоритмов машинного обучения" (ссылка, Реестровая запись №10106);
Для получения коммерческого предложения по лицензированию нужно отправить письмо на электронную почту hello@silero.ai с указанием:
- Названия вашего юрлица;
- Предполагаемого сценария использования;
- Какой-либо оценки по масштабу использования для примерного расчета сайзингов для коммерческого предложения;
Обновление от 2022-10-11
Публичная версия документации программного модуля Силеро для синтеза речи на русском языке доступна по ссылке. Она содержит информацию про:
- Описание функциональных характеристик;
- Информацию для установки и эксплуатации ПО;
Сайзинги
Актуальные сайзинги для наших дистрибутивов на базе Ubuntu и Astra Linux, версия 1.5.4. За этот период произошло радикальное ускорение синтеза речи и увеличение его качества.
В следующей мажорной версии опять ожидается также радикальное повышение скорости распознавания и синтеза, и качества распознавания.
Распознавание речи, CPU
Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz
| Сайзинг | Минимум |
|---|---|
| Файл AM | ru_small_v015_q.jit |
| Файл LM | ru_lm_v*.distro.model |
| RAM | 8 GB |
| Ядер процессора | 6+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Обязательно |
| --scale lm-consumer= | 8 |
| --scale am-consumer-short= | 1 |
| --scale am-consumer-long= | 1 |
| WORKERS (воркеры API) | 8 |
| AM_BATCH_DELAY | 0.05 |
| AM_BATCH_SIZE | 10 |
| AM_LANES | 3 |
| CPUSET_SHORT | 0-1 # 1 ядро |
| CPUSET_LONG | 2-5 # 2 ядра |
| CPUSET_LM | 6-11 # 3 ядра |
v1.5.4:
| Метрики | 4 "потока" | 8 "потоков" |
|---|---|---|
| Среднее время ответа, мс | 290 | 370 |
| 95-я перцентиль, мс | 480 | 670 |
| 99-я перцентиль, мс | 600 | 890 |
| Файлов за 1000 мс | 12 | 19 |
| Файлов за 500 мс | 6.0 | 9.0 |
| Секунд аудио в секунду (1 / RTF) | 41 | 63 |
| Биллинговые потоки | 6-12 | 10-16 |
| Секунд аудио в секунду на ядро | 6.8 | 10.3 |
v1.5.4_astra:
| Метрики | 4 "потока" | 8 "потоков" |
|---|---|---|
| Среднее время ответа, мс | 280 | 370 |
| 95-я перцентиль, мс | 470 | 680 |
| 99-я перцентиль, мс | 580 | 860 |
| Файлов за 1000 мс | 13 | 19 |
| Файлов за 500 мс | 6.0 | 9.0 |
| Секунд аудио в секунду (1 / RTF) | 42 | 64 |
| Биллинговые потоки | 6-12 | 10-16 |
| Секунд аудио в секунду на ядро | 6.8 | 10.3 |
Сайзинги на astra почти не отличаются и приведены для справки.
Распознавание речи, GPU
v1.5.4:
| Сайзинг | Рекомендуется |
|---|---|
| Файл AM | ru_xlarge_v015.model |
| Файл LM | ru_lm_v*.distro.model |
| RAM | 12 GB |
| Ядер процессора | 12+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Не обязательно |
| --scale lm-consumer= | 16 |
| AM_LANES | |
| WORKERS (воркеры API) | 16 |
| AM_BATCH_DELAY | 0.05 |
| AM_BATCH_SIZE | 10 |
| Совместимые GPU | (*) |
1080Ti:
| Метрики | 8 "потоков" | 16 "потоков" |
|---|---|---|
| Среднее время ответа, мс | 340 | 440 |
| 95-я перцентиль, мс | 520 | 650 |
| 99-я перцентиль, мс | 610 | 820 |
| Файлов за 1000 мс | 21.2 | 33.0 |
| Файлов за 500 мс | 10.6 | 16.5 |
| Секунд аудио в секунду (1 / RTF) | 71 | 111 |
| Биллинговые потоки | 12 - 18 | 16 - 24 |
3090:
| Метрики | 8 "потоков" | 16 "потоков" | 24 "потока" |
|---|---|---|---|
| Среднее время ответа, мс | 240 | 230 | 250 |
| 95-я перцентиль, мс | 340 | 350 | 370 |
| 99-я перцентиль, мс | 400 | 400 | 450 |
| Файлов за 1000 мс | 31.0 | 63.6 | 87.6 |
| Файлов за 500 мс | 15.5 | 31.8 | 43.8 |
| Секунд аудио в секунду (1 / RTF) | 105 | 214 | 295 |
| Биллинговые потоки | 15 - 20 | 30 - 40 | 42 - 50 |
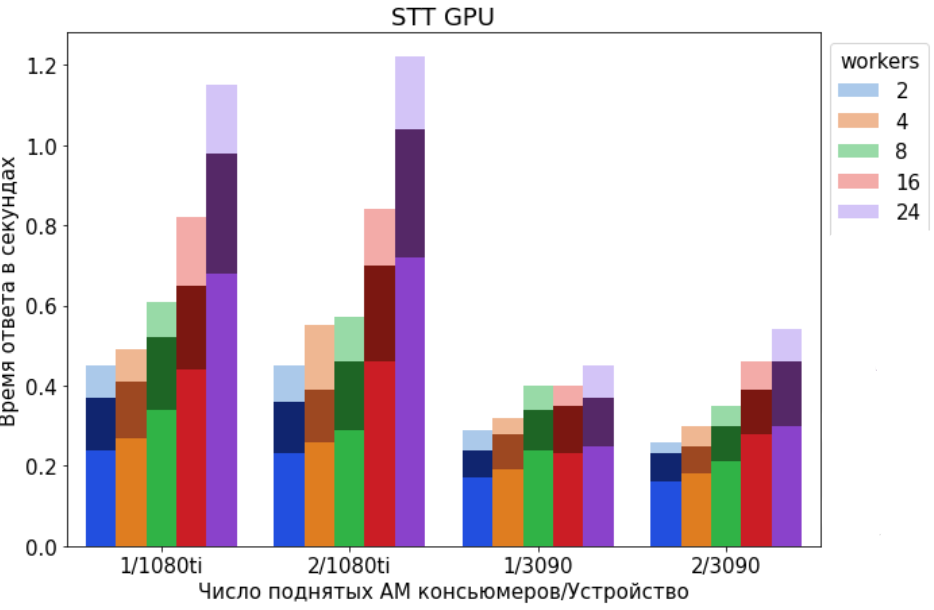
Время ответа в секундах в зависимости от числа поднятых AM-консьюмеров и количества параллельных потоков (workers), отправляющих запросы с аудио в API.
- Яркая палитра - среднее время ответа;
- Тёмная палитра - 95 перцентиль;
- Светлая палитра - 99 перцентиль;
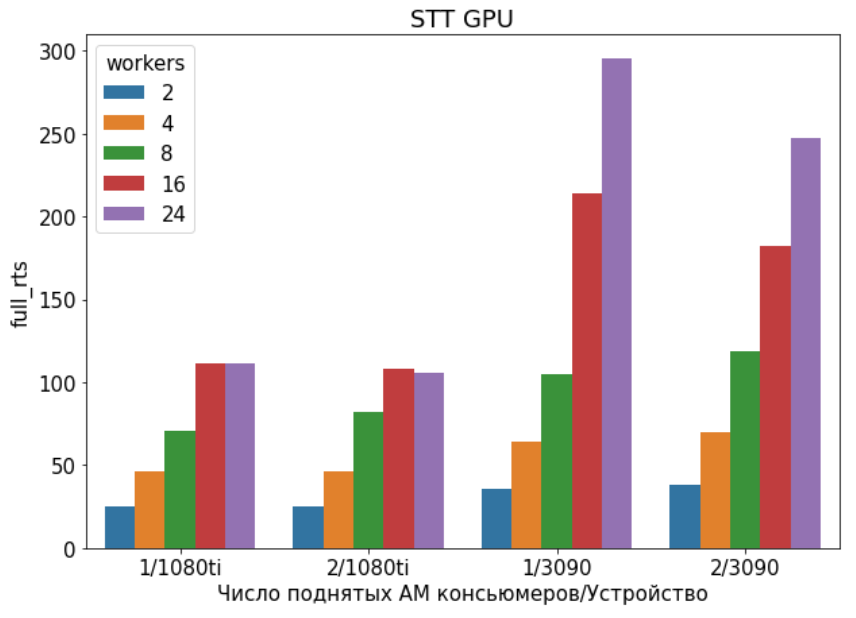
1/RTF - Количество секунд распознанного аудио за 1 секунду работы - в зависимости от числа поднятых AM-консьюмеров и количества параллельных потоков(workers), отправляющих запросы с аудио в API.
Синтез речи, CPU
Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz
| Сайзинг | Минимум |
|---|---|
| RAM | 3 GB |
| Ядер процессора | 2+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Не обязательно |
| --scale tts-consumer= | 1 |
| CPUSET_TTS | 0-3 # 2 ядра |
v1.5.4
| Метрики | 8KHz/1 "поток" | 24KHz/1 "поток" | 48KHz/1 "поток" |
|---|---|---|---|
| Среднее время ответа, мс | 130 | 260 | 460 |
| 95-я перцентиль, мс | 190 | 440 | 780 |
| 99-я перцентиль, мс | 220 | 520 | 1020 |
| Секунд аудио в секунду (1 / RTF) | 41 | 20 | 12 |
v1.5.4_astra
| Метрики | 8KHz/1 "поток" | 24KHz/1 "поток" | 48KHz/1 "поток" |
|---|---|---|---|
| Среднее время ответа, мс | 120 | 260 | 460 |
| 95-я перцентиль, мс | 180 | 440 | 820 |
| 99-я перцентиль, мс | 210 | 520 | 1070 |
| Секунд аудио в секунду (1 / RTF) | 44 | 21 | 12 |
Сайзинги на astra почти не отличаются и приведены для справки.
Синтез речи, GPU
v1.5.4
| Сайзинг | Рекомендуется |
|---|---|
| Файл TTS | tts_ru_v015_newacc.pt |
| RAM | 3 GB |
| Ядер процессора | 6+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Не обязательно |
| --scale tts-consumer= | 2 |
| WORKERS (воркеры API) | 8 |
| Совместимые GPU | (*) |
1080Ti SR=8000 Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 80 | 80 | 130 |
| 95-я перцентиль, мс | 90 | 120 | 170 |
| 99-я перцентиль, мс | 90 | 130 | 200 |
| Секунд аудио в секунду (1 / RTF) | 71 | 252 | 328 |
1080Ti SR=24000 Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 90 | 110 | 190 |
| 95-я перцентиль, мс | 120 | 170 | 250 |
| 99-я перцентиль, мс | 130 | 190 | 290 |
| Секунд аудио в секунду (1 / RTF) | 58 | 192 | 224 |
1080Ti SR=48000 Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 110 | 140 | 250 |
| 95-я перцентиль, мс | 140 | 230 | 360 |
| 99-я перцентиль, мс | 160 | 260 | 390 |
| Секунд аудио в секунду (1 / RTF) | 50 | 148 | 168 |
3090 SR=8000Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 50 | 50 | 70 |
| 95-я перцентиль, мс | 50 | 70 | 90 |
| 99-я перцентиль, мс | 60 | 80 | 100 |
| Секунд аудио в секунду (1 / RTF) | 114 | 416 | 624 |
3090 SR=24000Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 60 | 70 | 90 |
| 95-я перцентиль, мс | 70 | 90 | 120 |
| 99-я перцентиль, мс | 70 | 100 | 140 |
| Секунд аудио в секунду (1 / RTF) | 95 | 328 | 464 |
3090 SR=48000Hz
| Метрики | 1 "поток" | 4 "потока" | 8 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 70 | 80 | 120 |
| 95-я перцентиль, мс | 90 | 120 | 170 |
| 99-я перцентиль, мс | 110 | 140 | 180 |
| Секунд аудио в секунду (1 / RTF) | 80 | 272 | 352 |
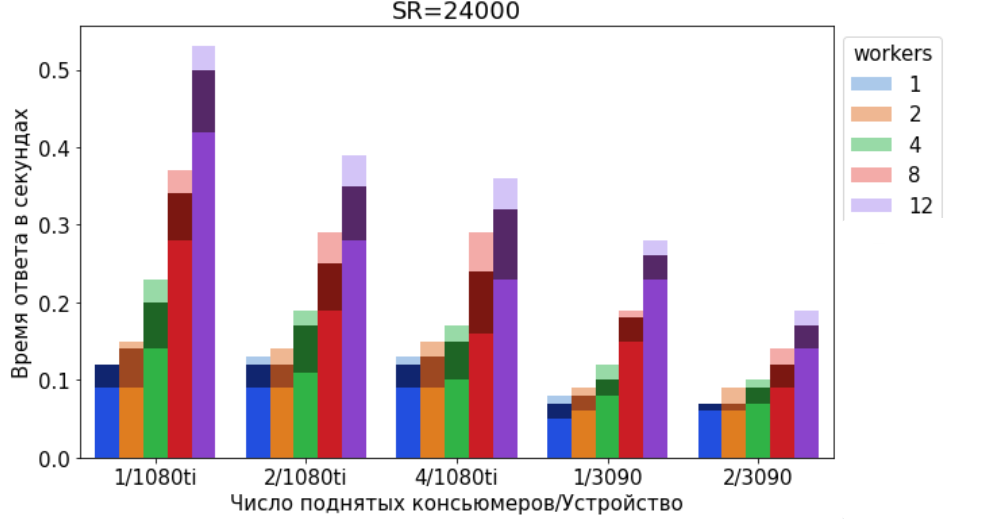
Время ответа в секундах в зависимости от числа поднятых TTS консьюмеров и количества параллельных потоков(workers), отправляющих запросы с текстом в API.
- Яркая палитра - среднее время ответа;
- Тёмная палитра - 95 перцентиль;
- Светлая палитра - 99 перцентиль;
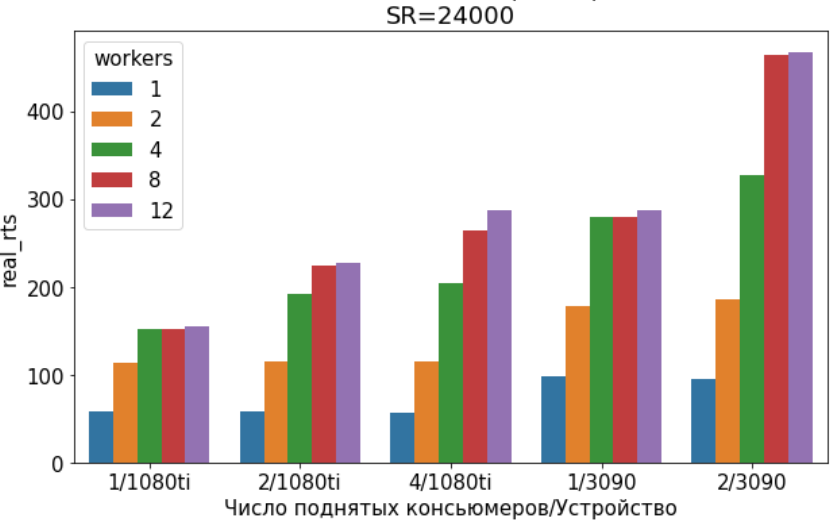
Количество секунд синтезируемого аудио за 1 секунду работы - в зависимости от числа поднятых TTS консьюмеров и количества параллельных потоков(workers), отправляющих запросы с текстом в API.
(*)
В целом подходят любые GPU Nvidia начиная с архитектуры Pascal, в частности:
- Любые игровые GPU Nvidia выше чем 1070 8+GB RAM с турбиной;
- Любые однослотовые GPU Nvidia серии Quadro 8+GB RAM (TDP 100 - 150W) с турбиной или пассивные;
- Nvidia Tesla T4, пассивная, TDP 75W;
- Любые карты лучше / мощнее;
Обновление от 2021-11-18
Сейчас в список наших основных поддерживаемых решений входят:
- Распознавание речи;
- Синтез речи;
- Детектор голоса и расстановка пунктуации и знаков препинания являются вспомогательными;
Дальше мы приведем сайзинги для GPU и CPU версии нашего распознавания и синтеза речи для недавнего масштабного релиза наших дистрибутивов v012:
- GPU сайзинг для распознавания речи;
- GPU сайзинг для синтеза речи;
- СPU сайзинг для распознавания речи;
- CPU сайзинг для синтеза речи;
GPU сайзинг для распознавания речи
| Сайзинг | Рекомендуется |
|---|---|
| Файл AM | ru_xlarge_v012.model |
| Файл LM | ru_lm_v*.distro.model |
| RAM | 12 GB |
| Ядер процессора | 12+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Не обязательно |
| --scale lm-consumer= | 16 |
| AM_LANES | |
| WORKERS (воркеры API) | 16 |
| AM_BATCH_DELAY | 0.05 |
| AM_BATCH_SIZE | 10 |
| Совместимые GPU | (*) |
1080 Ti
| Метрики | 8 "потоков" | 16 "потоков" |
|---|---|---|
| Среднее время ответа, мс | 320 | 440 |
| 95-я перцентиль, мс | 500 | 660 |
| 99-я перцентиль, мс | 630 | 820 |
| Файлов за 1000 мс | 22.4 | 33.2 |
| Файлов за 500 мс | 11.2 | 16.6 |
| Секунд аудио в секунду (1 / RTF) | 75 | 112 |
| Биллинговые потоки | 12 - 18 | 16 - 24 |
3090
| Метрики | 8 "потоков" | 16 "потоков" | 24 "потоков" |
|---|---|---|---|
| Среднее время ответа, мс | 240 | 230 | 290 |
| 95-я перцентиль, мс | 330 | 340 | 450 |
| 99-я перцентиль, мс | 390 | 400 | 530 |
| Файлов за 1000 мс | 31 | 63 | 75 |
| Файлов за 500 мс | 15.5 | 31.5 | 37.5 |
| Секунд аудио в секунду (1 / RTF) | 106 | 212 | 254 |
| Биллинговые потоки | 16 - 32 | 32 - 48 | 38 - 52 |
GPU сайзинг для синтеза речи
| Сайзинг | Рекомендуется |
|---|---|
| RAM | 3 GB |
| Ядер процессора | 8+ |
| Тактовая частота ядра | 3 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Не обязательно |
| WORKERS (воркеры API) | 8 |
| TTS_BATCH_DELAY | 0.1 |
| TTS_BATCH_SIZE | 8 |
| Совместимые GPU | (*) |
| Метрики | 8 "потоков" |
| Среднее время ответа, мс | 582 |
| 95-я перцентиль, мс | 1151 |
| 99-я перцентиль, мс | 1240 |
| Секунд аудио в секунду (1 / RTF) | 39 |
| Секунд аудио в секунду на батч | 4.9 |
СPU сайзинг для распознавания речи
| Сайзинг | Минимум |
|---|---|
| Файл AM | ru_small_v013_q.model |
| Файл LM | ru_lm_v*.distro.model |
| RAM | 8 GB |
| Ядер процессора | 6+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Обязательно |
| --scale lm-consumer= | 8 |
| --scale am-consumer-short= | 1 |
| --scale am-consumer-long= | 1 |
| WORKERS (воркеры API) | 8 |
| AM_BATCH_DELAY | 0.05 |
| AM_BATCH_SIZE | 10 |
| AM_LANES | 3 |
| CPUSET_SHORT | 0-1 # 1 ядро |
| CPUSET_LONG | 2-5 # 2 ядра |
| CPUSET_LM | 6-11 # 3 ядра |
Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz:
| Метрики | 4 "потока" | 8 "потоков" |
|---|---|---|
| Среднее время ответа, мс | 280 | 380 |
| 95-я перцентиль, мс | 490 | 720 |
| 99-я перцентиль, мс | 630 | 870 |
| Файлов за 1000 мс | 12 | 18 |
| Файлов за 500 мс | 6.0 | 9.0 |
| Секунд аудио в секунду (1 / RTF) | 41 | 62 |
| Биллинговые потоки | 6-12 | 10-16 |
| Секунд аудио в секунду на ядро | 6.8 | 10.3 |
CPU сайзинг для синтеза речи
| Сайзинг | Минимум |
|---|---|
| RAM | 3 GB |
| Ядер процессора | 2+ |
| Тактовая частота ядра | 3.5 GHz+ |
| 2 потока на ядро процессора | Да |
| AVX2 инструкции процессора | Обязательно |
| --scale tts-consumer= | 1 |
| TTS_BATCH_DELAY | 0 |
| TTS_BATCH_SIZE | 1 |
| CPUSET_TTS | 0-4 # 2 ядра |
Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz:
| Метрики | 1 "поток" | 2 "потока" |
|---|---|---|
| Среднее время ответа, мс | 1741 | 3225 |
| 95-я перцентиль, мс | 3853 | 6185 |
| 99-я перцентиль, мс | 4622 | 7737 |
| Секунд аудио в секунду (1 / RTF) | 6.5 | 3.5 |
| Секунд аудио в секунду на ядро | 3.25 | 1.75 |
Оригинальная Статья от 2020-12-05
Какое-то время назад мы публиковали целый ряд статей про нашу систему Speech-To-Text, а именно про:
- Её качество;
- Её скорость и пропускную способность;
- Про требования к ресурсам;
Понятно, что качество постепенно выходит на плато, и дойдя до какого-то уровня по качеству нужно задумать о миниатюризации и создании дистрибутивов. В этом посте я подведу финальные итоги нашему продолжительному процессу ускорения наших моделей и приведу финальные сайзинги дистрибутивов Enterpise Edition версии нашей системы. Пока по ряду причин публично мы писали про нее только тут.
Чем Мы Занимались Все Это Время
Может показаться, что мы ушли в подполье, но с тех пор многое изменилось и мы не сидели без дела:
- Мы выпустили публичную Community Edition версию наших моделей для нескольких языков. Нас даже похвалил Soumith Chintala;
- Cделали несколько глобальных рефакторингов кода, выпустили V2 версию нашей CE-edition модели для английского языка;
- Публично выпустили экспериментальную модель для украинского языка в рамках Silero Models для мотивации наших украинских коллег;
- Запустили несколько больших research-проектов и провели большую подготовительную работу для обширного обновления перезапуска (как говорится, stay tuned!). Будем выпускать новые публичные продукты when it's done;
Финальное Ускорение Наших Моделей
По ряду причин уже не буду тут вдаваться в детали, но финальную акустическую модель удалось существенно ускорить (настолько, что это практически перестало быть боттлнеком даже для CPU сайзингов!).
Метрики указаны в секундах аудио обработанных в секунду на 1 ядро процессора (1 / RTF на ядро):
| Batch size | FP32 | FP32 + Fused | FP32 + INT8 | FP32 Fused + INT8 | Full INT8 + Fused | New Best |
|---|---|---|---|---|---|---|
| 1 | 7.7 | 8.8 | 8.8 | 9.1 | 11.0 | 22.6 |
| 5 | 11.8 | 13.6 | 13.6 | 15.6 | 17.5 | 29.8 |
| 10 | 12.8 | 14.6 | 14.6 | 16.7 | 18.0 | 29.3 |
| 25 | 12.9 | 14.9 | 14.9 | 17.9 | 18.7 | 29.8 |
Может показаться, что скачок является слишком огромным, но мы просто не сидели без дела. Тут еще важно отметить, что цифры отчасти кажутся нереалистичными в сравнении с теми же 8+ RTS, о которых писал фейсбук в своей статье. Но тут важно понимать, что мы обрабатываем аудио батчами, а фейсбук - по одному кусочками по 750 ms. Плюс это идеальные условия, когда файлы по сути кормятся в акустическую сеть из памяти. В реальности все не так радужно (смотрите сайзинги ниже) и мы тратим гораздо больше времени на ожидание и коммуникацию.
Ускорения против базовой "маленькой модели":
| Batch size | FP32 + Fused | FP32 + INT8 | FP32 Fused + INT8 | Full INT8 + Fused | New Best |
|---|---|---|---|---|---|
| 1 | 14% | 14% | 18% | 42% | 193% |
| 5 | 16% | 16% | 32% | 48% | 153% |
| 10 | 15% | 15% | 31% | 41% | 130% |
| 25 | 15% | 15% | 39% | 44% | 130% |

Сайзинги и Дистрибутивы
Метрики акустической модели являются несколько абстрактными. В реальном деплое на скорость и пропускную способность (latency / throughput) влияет гораздо больше вещей - пост-обработка, архитектура сервиса, задержка сети, сериализация, коммуникация, итд итп.
По этой причине - мы просто провели огромную работу по расчету реальных сайзингов наших EE моделей и оптимизации гипер-параметров наших дистрибутивов.
Пара слов о методологии:
- Метрики рассчитаны для файлов длиной 1 - 7 секунд, которые "кормятся" в сервис в 4 - 8 - 16 потоков;
- Распределение длин файлов соответствует распределению длин файлов в реальных диалогах людей по телефону;
- Метрики рассчитаны для многопоточного веб-сервиса, что немного абстрагируется от сценария реального использования. Ну то есть если мы можем держать условно 8 потоков с условной гарантией в latency в 500 мс, то это значит, что правильно настроив конечную бизнес-логику, можно обрабатывать сильно больше, чем 8 одновременных звонков;
- Реальные люди не говорят одновременно, пока человек заканчивает вторую фразу мы уже усеваем обработать первую итд итп. Но это уже сильно зависит от реального бизнес-кейса;
Настройка Сайзинга Для GPU
| Сайзинг | Минимум | Рекомендуется |
|---|---|---|
| Диск | SSD, 256+ GB | NVME, 256+ GB |
| RAM | 32 GB | 32 GB |
| Ядер процессора | 8+ | 12+ |
| Тактовая частота ядра | 3 GHz+ | 3.5 GHz+ |
| 2 потока на ядро процессора | Да | Да |
| AVX2 инструкции процессора | Не обязательно | Не обязательно |
| Совместимые GPU | (*) | (*) |
| Количество GPU | 1 | 1 |
| Метрики | 8 "потоков" | 16 "потоков" |
| Среднее время ответа, мс | 280 | 320 |
| 95-я перцентиль, мс | 430 | 476 |
| 99-я перцентиль, мс | 520 | 592 |
| Файлов за 1000 мс | 25.0 | 43.4 |
| Файлов за 500 мс | 12.5 | 21.7 |
| Секунд аудио в секунду (1 / RTF) | 85.6 | 145.0 |
| Биллинговые потоки | 12 - 18 | 22 - 30 |
| Секунд аудио в секунду на ядро | 10.7 | 12.1 |
(*) Есть 3 типа подходящих GPU:
- Любые игровые GPU Nvidia выше чем 1070 8+GB RAM с турбиной;
- Любые однослотовые GPU Nvidia серии Quadro 8+GB RAM (TDP 100 - 150W) с турбиной или пассивные;
- Nvidia Tesla T4, пассивная, TDP 75W;
Настройка Сайзинга Для CPU
| Сайзинг | Минимум | Рекомендуется |
|---|---|---|
| Диск | SSD, 256+ GB | SSD, 256+ GB |
| RAM | 32 GB | 32 GB |
| Ядер процессора | 8+ | 12+ |
| Тактовая частота ядра | 3.5 GHz+ | 3.5 GHz+ |
| 2 потока на ядро процессора | Да | Да |
| AVX2 инструкции процессора | Обязательно | Обязательно |
| Метрики | 4 "потока" | 8 "потоков" |
| Среднее время ответа, мс | 320 | 470 |
| 95-я перцентиль, мс | 580 | 760 |
| 99-я перцентиль, мс | 720 | 890 |
| Файлов за 1000 мс | 11.1 | 15.9 |
| Файлов за 500 мс | 5.6 | 8.0 |
| Секунд аудио в секунду (1 / RTF) | 37.0 | 53.0 |
| Биллинговые потоки | 6 - 9 | 8 - 10 |
| Секунд аудио в секунду на ядро | 4.6 | 4.4 |
Комментарии по Сайзингам
- В реальности со всем фаршем даже у сервиса с GPU получается только 10 - 15 RTS на одно ядро процессора (хотя теоретический RTS самой модели на GPU находится где-то в районе 500 - 1,000). В теории число воркеров CPU на 1 GPU можно наращивать больше, чем мы пробовали, но мы упираемся в удорожание процессоров;
- CPU-версия сервиса показывает только в районе 5 честных RTS, что немало, но она скорее оптимизирована как баланс между гарантиями по latency и throughput;
- Метрики настоящие и честные и подбор параметров стоил много боли и страданий. Если честно - я вообще не видел, чтобы кто-то вообще показывал перцентили реальных систем;
- Многие крупные проекты просят 50 одновременных разговоров, поэтому иметь возможность покрыть такой проект используя всего 2 GPU (+ резервирование) это довольно круто;
- Использование GPU сервиса где-то в 2-3 раза дешевле, чем если считать все только на CPU;